Website categorization is assigning one or more of predefined categories to a given website, based on its content.
We have developed one of the most accurate Website Categorization APIs, with websites classified in over 1000 content categories. You can try it out (for free) here:
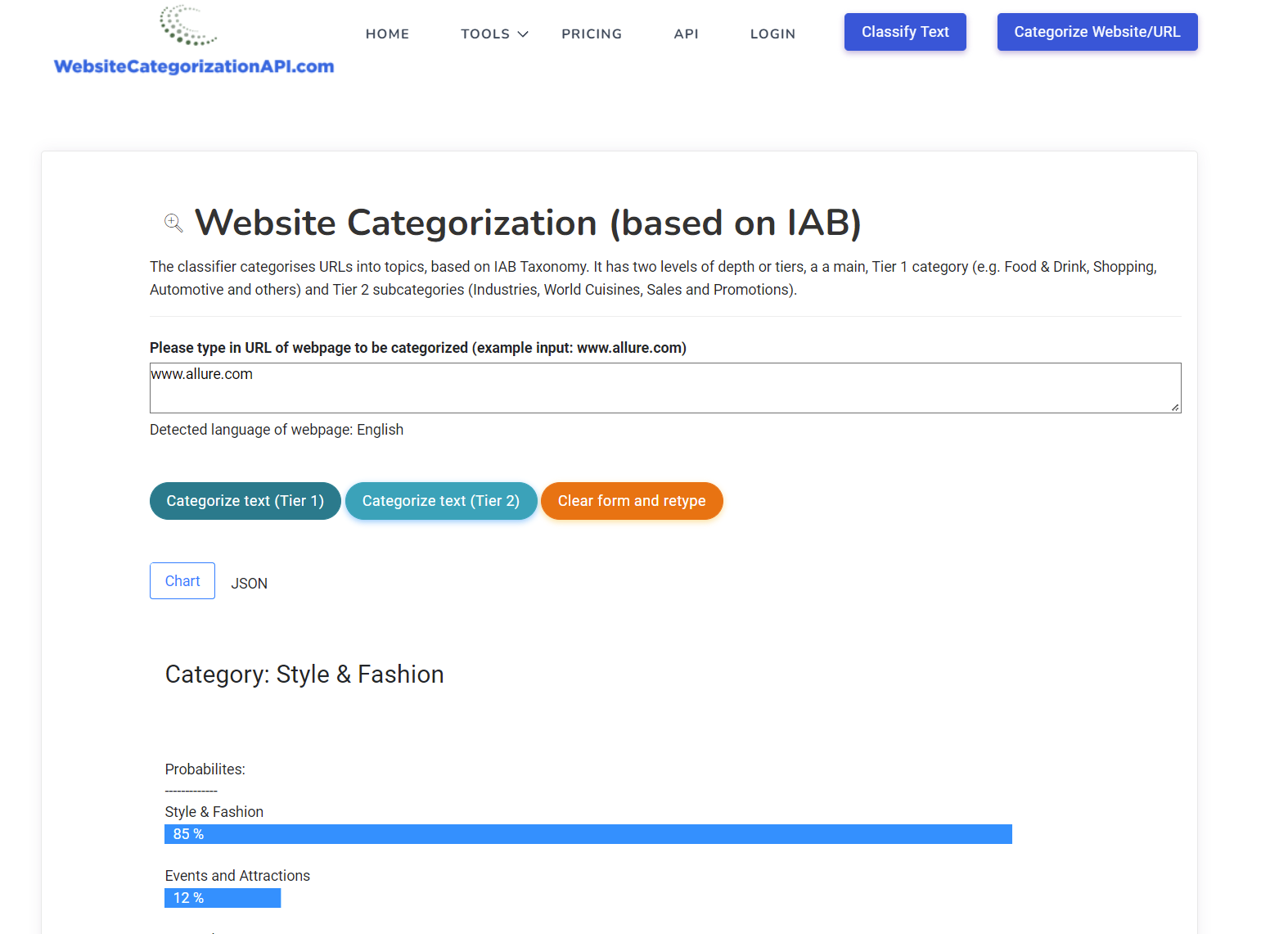
Whereas most of the Categorization APIs restrict themselves only to IAB taxonomy, the Websitecategorizationapi.com that we developed not only provides results according to IAB definitions, but also supports custom E-commerce categories (using Google Product Taxonomy).
One of its cool features is the explainability – the ability to explain why the machine learning model selected the category for given website.
Example for website of NYTimes:
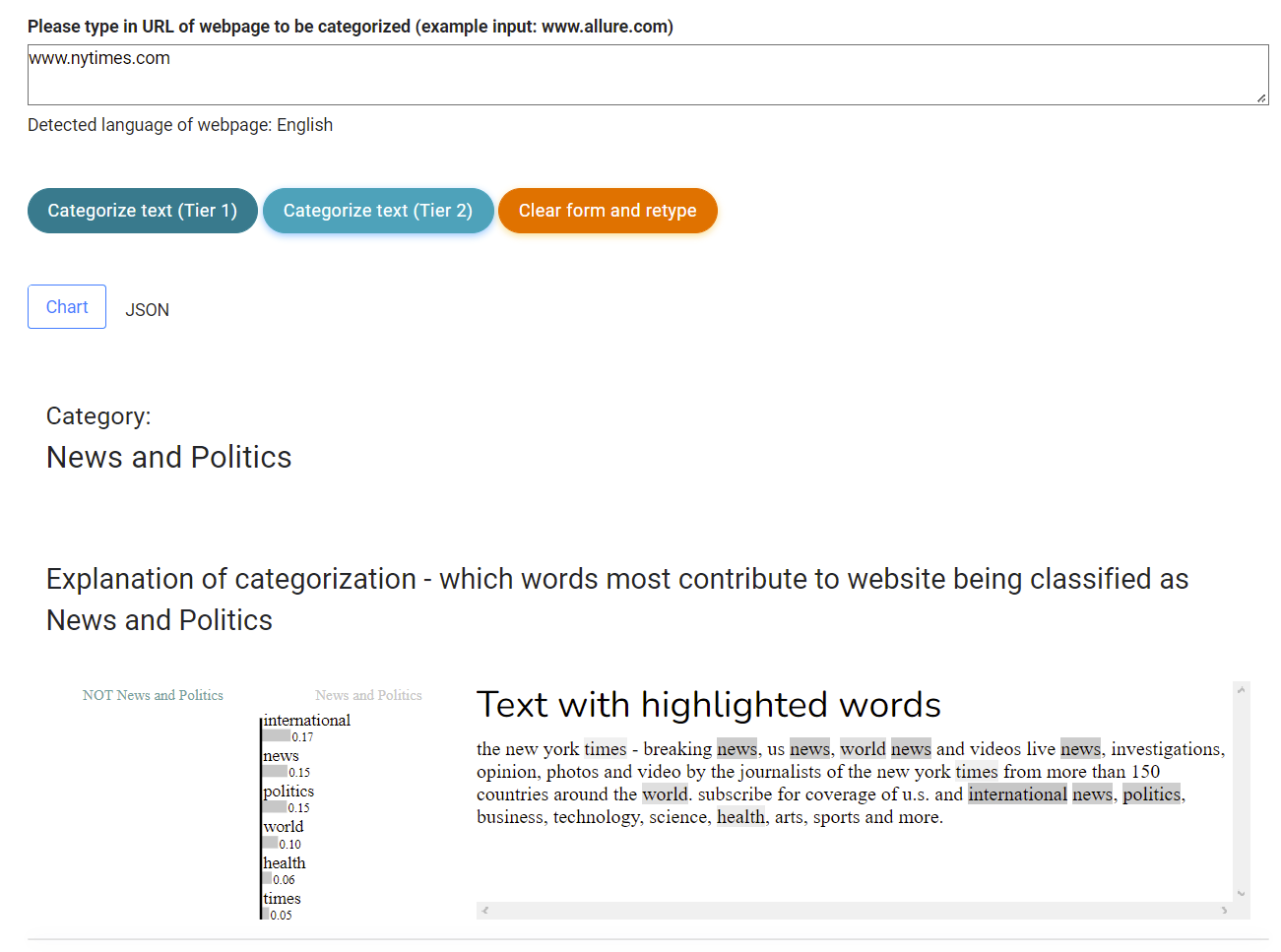
How does the service provide classifications?
The Website Classifier is using a custom trained machine learning model, for both IAB categorizations and E-Commerce categorizations. The machine learning pipeline consists of using Natural Language Processing (NLP) to extract relevant features from text which are then sent as input to the Machine Learning classifier model. Both IAB and E-Commerce classifiers developed by the company are among the most accurate ones currently available on the market for these tasks.
Use cases of URL categorization API
Website categorization API services are ideal for many use cases.
There are many cases for online offering, which supports live, real-time full path URL categorization API classifications as well as for offline databases.
The offline databases are ideal if a company wants to build own products and services based on it. This can be as part of startups offering new Saas services/products or they can be used in OEM companies, large enterprises for both internal and external applications.
Website classifiers can be further used for marketing, where an advertiser can classify potential publishers into categories and then select those websites for placement of ads which are in the same category as the client which wants to place ads.
Marketing apps can be supported by both real-time classifiers, as well as offline databases of companies and domains already being classified.
Another use case of URL classification API is cybersecurity. The company can set up an online filtering system and disallow access (from internal networks) to any external websites that are in particular categories, e.g. gaming, shopping and similar, helping protect employees and guests on own networks from potential cybersecurity incidents. By restricting access to gaming sites, the company can also help keep productivity high.
How does Websitecategorizationapi.com categorize websites
Websitecategorizationapi.com supports both offline classification as well as real, live classification of websites, which means that the user submits the URL, the service fetches its content, sends it to the NLP pipeline and then the ML classifier which outputs the resulting classification in JSON format.
The service provides you with example code to categorize websites in various programming languages, including python, so you can start working with the service and start getting categorizations immediately.
Support of 100+ languages for URL classification API
The API service from Websitecategorizationapi.com supports as part of paid plan, content written in 100+ languages. The service uses custom neural machine translation (NMT) models to translate the languages on the fly to English language, as the ML classifiers were trained on English language texts. If a language is not among the 100+ that the service supports, the company will add it on request.
Supported Taxonomies
The service supports two main taxonomies: IAB (from Internet Advertising Bureau) and Google Product Taxonomy. IAB is especially suitable for advertising, because it was developed with that purpose in mind and the categories reflect that. You can check them out here: https://iabtechlab.com/standards/content-taxonomy/
Here are some of the top categories for Tier 1 IAB:
Automotive
Books and Literature
Business and Finance
Careers
Education
Events
Holidays
Attractions
Shopping
Personal Celebrations & Life Events
Family and Relationships
Fine Art
Food & Drink
Healthy Living
Hobbies & Interests
Home & Garden
Medical Health
IAB regularly revises their taxonomy to reflect the introduction of new products. The service is keeping track of any revisions and updates its machine learning models accordingly. In this way, if you want to classify new, just recently introduced products on the market, the ML models will be able to deliver high accuracy classifications on these new products as well.
Main advantages of Websitecategorizationapi.com
Main advantages of the service are:
– one of the most accurate categorization services on the market
– supports more categories than most of other services (including 1000+ categories for E-Commerce)
– can be easily integrated in your own services and products
– dedicated customer support to help you with integration and customization
– detailed API documentation and supporting code examples which allow you to quickly start with using the API endpoints
– supports a large number of use cases
– by default it uses live, real-time full path URLs, unlike many other services which can serve you “stale” results from previous classification runs
– affordable plans, with discounts for startups
– you can build your own products and services on offline databases provided by the service (with millions of already classified URLs)
Examples of classifications for domain categorization:
IAB: Business & Industry -> Computers & Electronics -> Software & Internet -> Software Development, Design and Engineering
E-Commerce: Consumer Electronics, Tablets, and Portable Devices -> Consumer Products -> Computers, Parts and Accessories-> Software
Machine learning models
Many machine learning models can be used for text classification purpose. We are adding below some of them with introduction for each one.
Multinomial Naïve Bayes (NB)
Multinomial Naïve Bayes (NB) is easy to implement and scale, and performs well on text data. It is used widely in computer science, especially in text classification.
A multinomial distribution is a generalization of a binomial distribution. A binomial distribution describes the probability of k successes in n trials with probability p of success. The multinomial distribution describes the probability of observing counts for each one of k different outcomes after n trials.
The multinomial naive Bayes classifier is suitable for classification with discrete features (e.g., word counts for text classification). The multinomial distribution normally requires integer feature counts. However, in practice, fractional counts such as tf-idf may also work.
Logistic Regression (LR)
A logistic regression (LR) is a statistical technique that can be used to model the probability of a binary outcome. In other words, it can be used to determine which factors affect an event occurring and by how much. For example, you might use LR to determine what factors affect your likelihood of getting into a good college, or of being accepted into graduate school, or to determine how likely it is that you will be able to land a high-paying job after graduation.
Support Vector Machines
Support vector machines is a machine learning algorithm which is used for supervised learning, classification and regression.
Types of Support Vector Machines are:
Classification: There are two types of classification support vector machines i.e. binary SVM and multi-class SVM. Multi-class SVM is used for classification with more than 2 classes. It is also called as one-vs-all (OVA) or one-vs-rest (OVR). Binary SVM is used for classification with two classes only.
Regression: Linear SVM is used when the output variable value can take any real value in the range [0,1].
General Principle: The general principle behind all types of support vector machines is same, that to find a hyperplane in an n-dimensional space so that it separates the data points from different classes perfectly.
Stochastic Gradient Descent
Stochastic Gradient Descent is an algorithm used to train a machine learning model. It is a gradient-based optimization method that computes the gradient of the loss function with respect to the model parameters, which it then uses to update the parameters in a direction (and in an amount) that will reduce the loss.
The stochastic part of Stochastic Gradient Descent comes from the fact that each iteration of the algorithm uses a random sample from the training data (or a mini-batch) to compute the gradient and update the parameters, whereas when using batch gradient descent we would need to use all of the training data at once.
The key difference between Stochastic Gradient Descent and Batch Gradient Descent is that the former will get noisy estimates of the gradient, but will be much faster since it uses less data. However, Batch Gradient Descent calculates more precise gradients, but takes much longer since it’s using more data. The tradeoff is that Stochastic Gradient Descent will never converge to find exactly the global minimum because of noise in estimating your gradients, but it’ll find one that’s close enough. Batch Gradient Descent on the other hand may find a better overall minimum.
k-Nearest-Neighbors algorithm
The k-Nearest-Neighbors algorithm (kNN) is an non-parametric method used for website classification and regression. In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-NN is used for classification or regression:
In k-NN classification, the output is a class membership. An object is classified by a majority vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor.
Random Forests
Random Forests is a machine learning algorithm that can be used for both classification (e.g. domain classification API) and regression. It’s an ensemble method, which means it combines the results from several “weak” individual models to provide better performance than a single “strong” model. This kind of model is great for things like consumer behavior predictions, financial modeling, and medical diagnosis.
Ensemble learning methods are made up of a set of classifiers—e.g. decision trees—and their predictions are aggregated to identify the most likely result.
In 1996, Leo Breiman described the bagging method, where we select random sample of data in a training set using replacement—individual data points can be selected thus more than once. After several data samples are created, these different ML models are then trained, and the average or majority of those predictions lead to a more accurate estimate. This method helps decrease the variance in a noisy dataset.
Gradient boosting
Gradient boosting is a machine learning technique in the form of an ensemble of weak prediction models. It builds the model in a stage-wise fashion like other boosting methods do, and it generalizes them by allowing optimization of an differentiable loss function.
Technically, gradient boosting is an ensemble method. In an ensemble method, many learning algorithms like the one used for web categorization are employed to obtain improved predictive performance than could be generated from any of the constituent learning algorithms alone. An ensemble method usually combines weak learners (models that achieve only slightly better accuracy than random guessing, such as small decision trees) to produce a powerful committee (ensemble) that can make accurate predictions for most new samples.

