Website categorization is an important task in the field of text classification.
If you came across this website looking for tool for website categorization, check it out (for free) here:
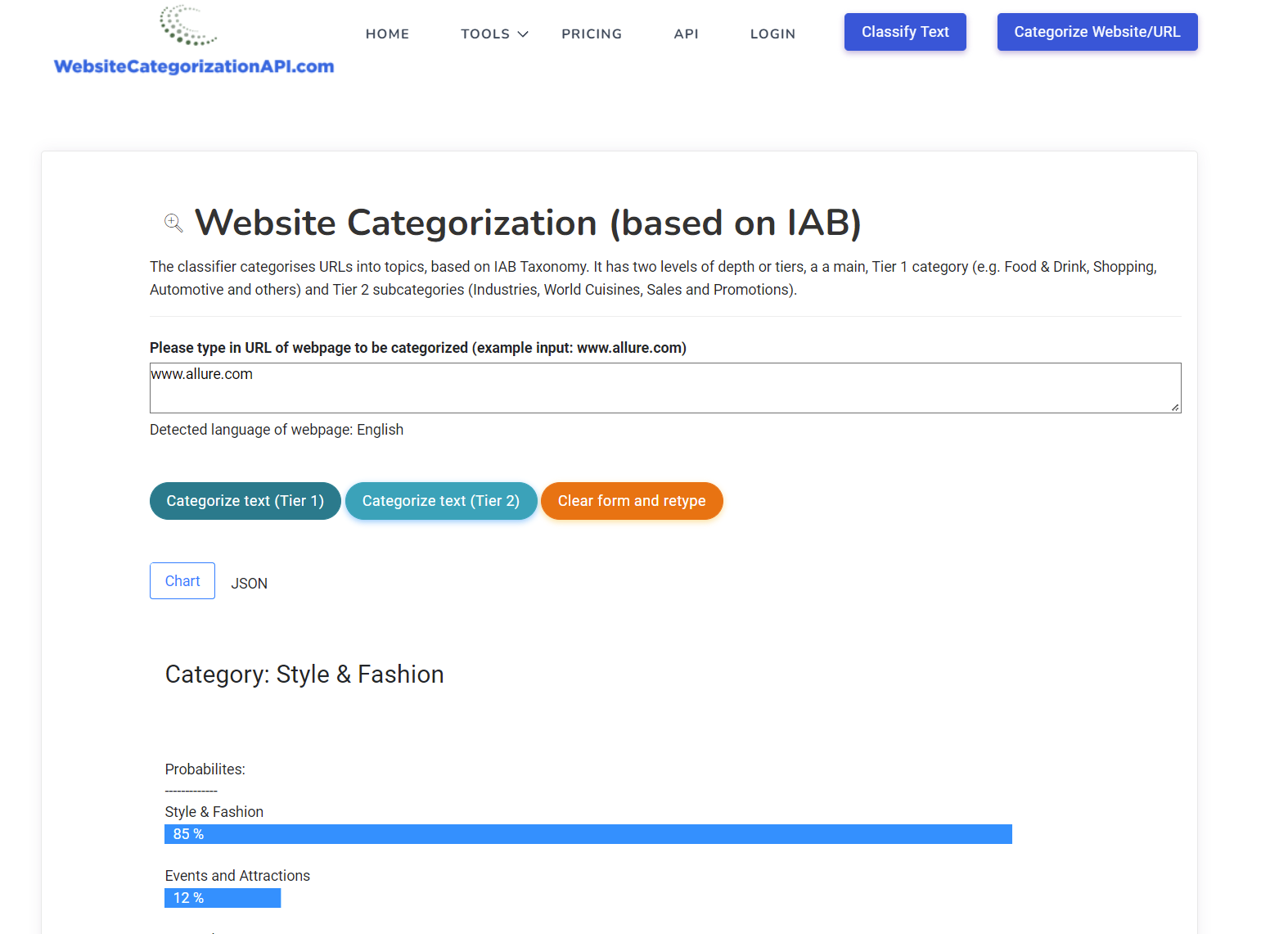
If you are interested in learning more about this topic, please read on.
Main goal of website categorization is to assign one or multiple categories to a given website, based on its content. E.g. if the website is about news then its category might be News.
But what about the possible categories. How does one know which categories to assign?
There are pre-defined categories available for that. The most well known one is the one from Internet Advertising Bureau or IAB. Its primary goal is to help advertisers define categories of websites so that they can select the correct publishers on which to advertise their ads. If a shopify online store from United States with clothing wants to advertise then they would like to do that on the website that is clothing related.
This definition of categories is also known as taxonomy, in this case IAB taxonomy. Taxonomies can number 1000+ categories for lower level Tiers. Many ecommerce companies, especially big retailers like WalMart, Target and so on have their own taxonomies defined, to better suit their own inventories.
The next question is how does one go about actually doing website categorizations. In practice, this is usually done using a machine learning model, thus in automated way.
There are more than 300+ million domains present on the internet with literally trillions of URLs (webpages) that can be classified. So there is really no other way other than an automatic one to categorize so many websites and URLs.
One subset of website categorization is the one that targets e-commerce categorizations or categorizing of products. This is e.g. suitable if we dealing with online stores that want to have their products categorized.
In this case a better taxonomy than IAB, which is meant for general texts, is rather the one from either Google or Facebook, which are more focused on products and have many more product, e-commerce categories than the one from IAB.
Here is the link to more information on Google Taxonomy: https://www.google.com/basepages/producttype/taxonomy-with-ids.en-US.txt
And here is more information on Facebook product categorization taxonomy: https://developers.facebook.com/docs/marketing-api/catalog/guides/product-categories/
A nice introduction to website categorization can be found here: https://dev.to/airesearcher/website-categorization-use-cases-taxonomies-content-extraction-2onp
and here:
https://categorization.hashnode.dev/website-url-categorization
Website categorization machine learning models are those that can be generally used for text classifications.
One can apply standard models for text classification, like Naive Bayes, SVM models, Logistic regression. Or use the neural nets, e.g. LSTM model, GRU model, recurrent neural nets and even ensembles of different neural net models.
An important part in website classification is also text extraction, because a typical website may contain in its DOM tree many HTML elements and tags that are not relevant for predicting category of webpage, e.g. menus and footers.
Text extraction is the method where we try to keep only the relevant parts of the text, to be used for categorization.
If you want to learn more about website categorization you can also check out the sliders on this topic: https://slides.com/categorization or twitter accounts for website categorization: https://nitter.net/webcategories and https://nitter.koyu.space/webcategories

