Our company has developed a sophisticated machine learning model that categorizes websites according to the widely used IAB taxonomy, which includes over 440 categories and supports both Tier 1 and Tier 2.
Using this model, we have classified millions of website domains and made this available in form of Offline Categorization Database.
Many of our clients, ranging from smaller startups, unicorns, to multinationals have found value in integrating this offline URL Database into their applications, serving a variety of use cases.
We invite you to explore the potential of large-scale, precise website categorization and consider our offline URL Database as a tool to enhance your business operations.
You can find more information and purchase options here:
https://www.websitecategorizationapi.com/url_database.php
Distribution of categorizations for 5 million domains from our website category database
Here is a distribution of Tier 1 categories for 5 million domains taken from the offline database:
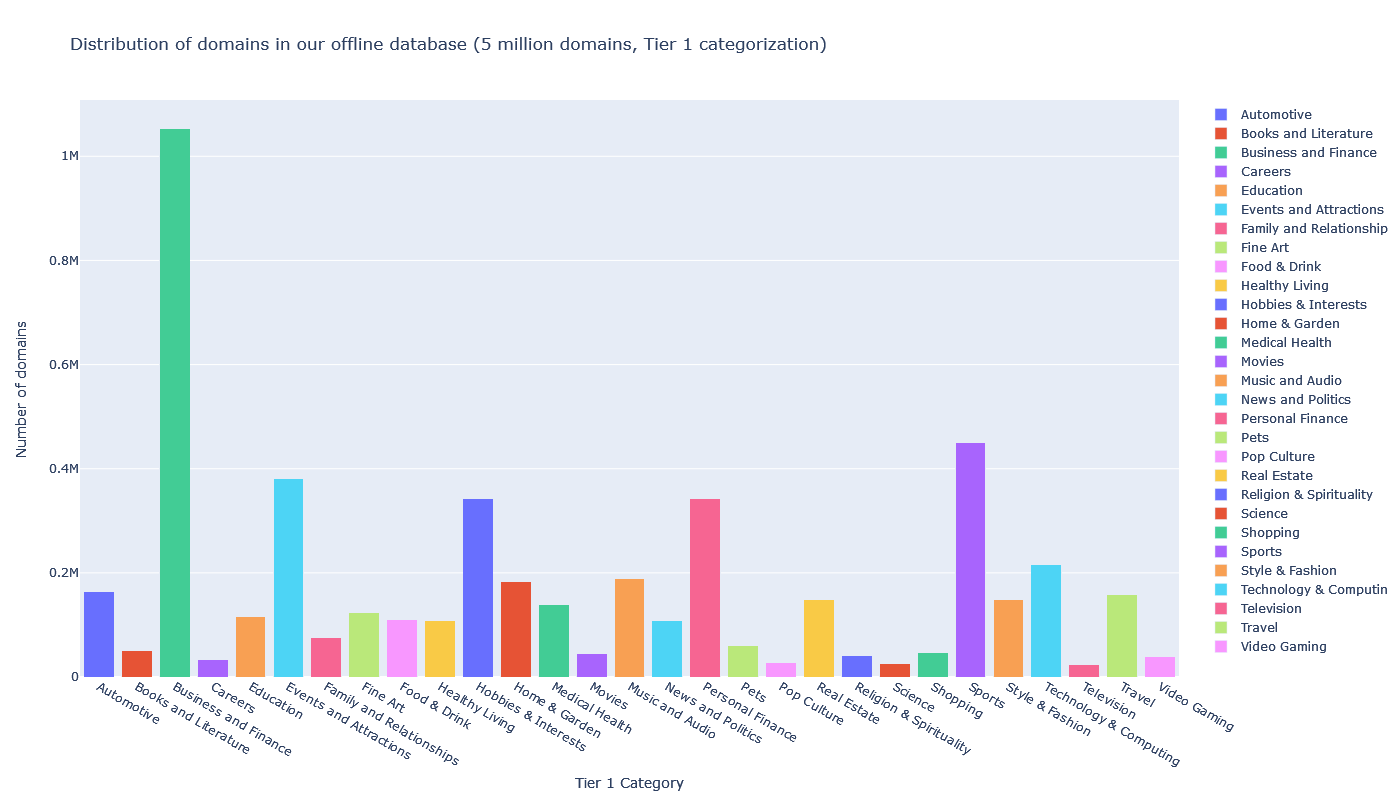
The most frequent domain categories are Business and Finance, Sports, Personal Finance, Hobbies & Interests, Technology and Computing, Events and Attractions.
For Tier 2 categories distribution, for sample from total set (only top 50 shown, to make chart readable) for a sample of top websites is:
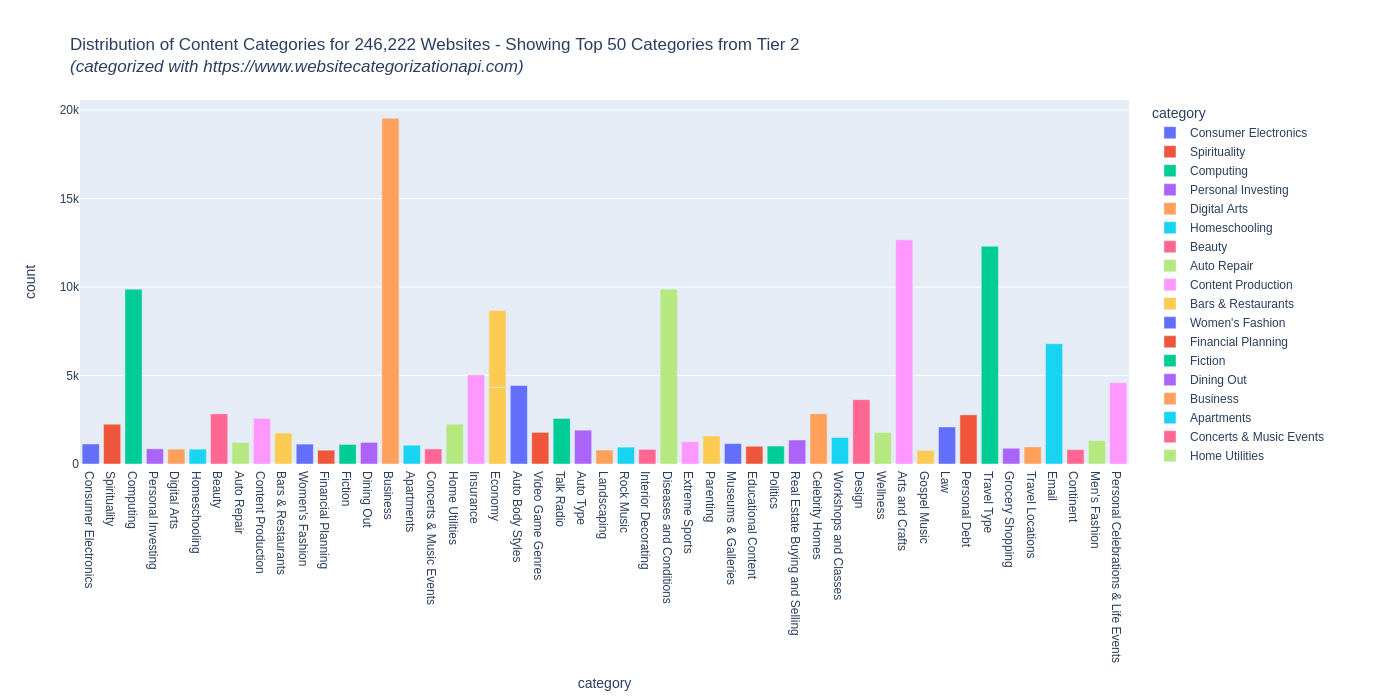
Business is the most common category, followed by Arts and Crafts, Travel Type.
An important part of many services in fields of web content filtering, AdTech marketing, cybersecurity, brand safety, contextual targeting (to name just a few) is a large and actively maintained URL database which contains, for each URL, categorized attributes like content category, safety classification and others.
In the rest of this article we will introduce you to the typical structure of URL database and how it is obtained.
Number of URLs and domains on internet
First let us address the question of URLs and domains. Did you know that there are more than 360 million of domains registered, according to 2021 stats from Verisign. Of those, around 15% are active.
Of course, each domain can have many subpages, leading to number of URLs in billions. As an example, the latest batch from well known crawler organization Common Crawl: https://commoncrawl.org/2022/02/january-2022-crawl-archive-now-available/
has found 2.95 billion webpages, this is just in a single crawl data set. Common crawl is a great way of analyzing website data and has many useful tools available for quicker parsing.
E.g. if you want to find all URLs that have some string like “/pricing.php” in their URLs you can use the common crawl columnar index and parse it. The columnar index data is stored in parquet format. You can learn more about parquet format here: https://parquet.apache.org
The sheer number of URLs existing in today’s web, with millions new added each day, means that any kind of categorization of URLs must be automated.
With machine learning by far the best choice for classifications, most categorisers for URLs, whether for content filtering or safety, are supervised machine learning models, belonging to the class of text classification models.
URL database – what kind of categories do we assign to URLs?
The type of categories that we assign to URLs depends on our objective. Let us say that our URL database will be needed in the AdTech company or marketing in general (if you are interested in learning more about AdTech, we created an introduction to main parts at the end of the blog post).
We have an advertiser A from specific industry, e.g. Automotive who wants to place the ads on websites of publishers. In order for ads to have a better conversion, advertiser should preferably advertise the ads on publishers websites that have the content that is from Automotive sector. Visitors of such websites are more likely to be interested in ads that are from an Automotive company.
But how do we know which webpages have Automotive content?
This is where the URL database helps.
It was generated using machine learning model classifier applied on billions of URLs and for each URL identifying the category of content, then storing this in URL database.
How can we store data in URL DataBase?
The AdTech company now just has to download the URL database and integrate it in existing app.
The categorization data in database itself can be stored in variety of ways. It can be stored in an SQL database format, NoSQL format or simply in text files, e.g. storing all URLs or domains that belong to specific category in the same text file.
URL Category Taxonomy for Web Content
When the objective is classification of web content, then one can use either own, custom taxonomies or the taxonomies that are standard in respective industry.
For marketing, the common standard of classifying content is the taxonomy from IAB, latest revision is available here:
https://iabtechlab.com/press-releases/tech-lab-releases-content-taxonomy-3-0/
If one is interested in classifying website content that is from Ecommerce field, then taxonomy from Google Products may be more appropriate:
https://www.google.com/basepages/producttype/taxonomy-with-ids.en-US.txt
URL categorization service from https://www.websitecategorizationapi.com supports both taxonomies.
You can try out both classifiers (for general content and for Ecommerce) here:
https://www.websitecategorizationapi.com/demo_dashboard_iab/
https://www.websitecategorizationapi.com/text-classification
Free URL Categorization Database
If you are interested in checking out only the categories of top 500 domains in the world, we offer this open source database here:
https://www.websitecategorizationapi.com/sample_categorized_domains.csv
Conclusion
In this blog post we introduced you to more information on how the URL databases are used and how they are created. We also provided a link to URL database service that you can use in your apps, services or for other purposes.
Website categorization API categories
Website categorization services usually use IAB categories.
Here are the top IAB1 categories:
Real Estate Fine Art Pop Culture Home & Garden Business and Finance Hobbies &Interests Events and Attractions Personal Finance Travel Careers Shopping Family and Relationships Education Healthy Living Television Books and Literature Technology & Computing Style & Fashion Pets Movies News and Politics Automotive Religion & Spirituality Sports Food & Drink Medical Health Science Music and Audio Video Gaming
The list of IAB2 categories is much larger and includes hundreds of categories.
Adding a small selection below:
Design Celebrity Homes Houses Home Improvement Arts and Crafts Real Estate Buyingand Selling Economy Interior Decorating Vacation Properties Smart Home Apartments Insurance Industrial Property Gardening Personal Debt Industries HomeAppliances Remodeling & Construction Images/Galleries Travel Type Personal Celebrations & Life Events Landscaping Home Security Bars & Restaurants Home Utilities Retail Property Parks & Nature Outdoor Decorating Horror Movies Amusement and Theme Parks Land and Farms Career Planning Fashion Events SeniorHealth Museums & Galleries Party Supplies and Decorations Extreme Sports Personal Care Diving Comedy TV Birds Cats Reality TV Indie and Arthouse Movies Dining Out Cinemas and Events Business Eldercare
IAB1 and IAB2 are included in website categorization API that can be used from NodeJs as well.
Frequently asked questions
What is a URL database?
URL Database is a collection of URLs or links to subpages, usually with having some attribute determined for them, e.g. content category, language, author, root domain, residing IP, number of tokens (content length), topics mentioned in URL, and others.
How do I find the URL category?
Follow the steps: 1. decide which taxonomy is most appropriate (IAB or Ecommerce), 2. submit your URL to the WebsitecategorizationAPI tool (in dashboard) or use our API endpoints for this purpose. 3. You will obtain within 10 seconds and you can use the main predicted category or use all categories which have confidence higher than your set threshold.
AdTech Glossary
AdTech is a rapidly growing industry, with new business models and technologies being developed every day. We created a taxonomy of these categories so that you can easily navigate this space.
– Advertisers: A company that wants to sell goods or services to another company. They may want to advertise their products, or they may be looking for ways to improve their own internal processes through data collection and analysis.
– Ad Networks: A collection of online publishers who deliver ads based on the content that is displayed on their website or application. These networks usually have thousands or millions of websites under their umbrella, and are able to serve ads that are relevant to the user’s interests at the time they visit them.
– Demand Side Platforms (DSP): A company that manages digital advertising campaigns for its clients by buying ad space from publishers and then reselling it at a higher price than what they paid for it in order to make a profit off of each impression sold through their platform.
– Supply Side Platforms (SSP): A company or network that sells ad space directly from publishers such as newspapers or news sites through an automated auction process where advertisers bid on how much they are willing to pay per impression delivered