Ensemble approach enables us to improve accuracy of our machine learning models by pooling or ensembling their predictions together. If the individual base models are sufficiently diverse with respect to each other, the combined, ensemble method may actually have a better performance than any single base model.
Power of ensemble learning
Let us discuss with a simplified example from transmission or information theory why this may be so. We will see why the “wisdom of the crowds” actually has some natural foundation.
Let us say that we want to transmit information about something, from sender A to sender B.
We will simplify what we want to transmit, it will just be a series of 0s and 1s. Our message to be transmitted will be: 101.
Our transmission will travel over different wires and sometimes errors occur. 1 should be transmitted as 1 but instead turns to 0 on receiving at sender B. Or vice versa.
We do the transmission four times and the following transmissions are received:
101
111 (error)
001 (error)
101
Twice, we got an error in transmission. Let us now apply majority voting ensemble method on this transmission, it means the following: for each position in transmission we will take as the correct one the value which got the most “votes”.
The votes in our case are:
position 1: 3 votes for 1, 1 for 0
position 2: 3 votes for 0, 1 for 1
position 3: 4 votes for 1
The majority voted ensemble result is thus 101 and equal to input message. Even though we had two errors in transmission we could recover from the errors and get the correct final result. It illustrates the power of ensembling.
This is why the wisdom of the crowd may be a stronger concept than we may assume. Those opinions on the edge just get evened out at the end. It also shows why it makes sense to have different kind of individuals in your team and that the recruiting should strive for this, especially in teams like data science, AI, machine learning and others.
Note however that ensembling works well only when the errors are not correlated. If both errors in our transmission occured at same position, we would get a tie in the case above.
We can easily relate this to machine learning by reinterpreting the 101 as the results of classification for 3 classes. And the transmission as 3 distinct machine learning models. Even though 2 machine learning models in our ensemble made mistakes in one of the classes, the majority voting ensemble would still produce correct classification. Again, note that two machine learning models made different errors.
In the second part of the article we will discuss what kind of ensembling methods one can apply in machine learning.
Ensembling models
We generally distinguish between the following types of ensemble methods:
- averaging
- weighted average
- bagging
- boosting
- stacking
- blending
Averaging
In averaging based ensembling the main idea is to simply average the predictions of the base models. We could e.g. build the following base models:
- logistic regression
- linear regression (lasso, ridge)
- decision trees
- random forests
- support vector machine
- gradient boosting machine
- xgboost
- lightbm
- lstm deep neural net
- cnn neural net
And then average its predictions if we are dealing with regression problem. If we have a classification problem we may employ majority voting.
Weighted average
Weighted average ensembler is similar to simple averaging, except we give different weights to different models. We could e.g. find out that out of all base models, xgboost performs best in terms of f1, precision, accuracy, recall or ROC AUC and thus weight it more than others.
Bagging
In bagging approach to ensembling, we form base models by taking the same machine learning model e.g. decision tree, but train it on different parts of the training set. We obtain these sets by sampling from complete training set with replacement. This means that in some set the same data instances may actually be repeated.
Bagging name derives from Boostrapping and it was in 1994 proposed by L. Breiman, the “inventor” of random forests.
Typical example of bagging is training a decision tree on different samples, leading to a random forest machine learning algorithm.
Bagging helps in reducing variance of machine learning model. Variance can generally be defined as sensitivity of machine learning model to input data or how much the parameters of the model will change if we modify the training data. Machine learning problems suffer from bias-variance trade-off. If we try to decrease variance, the bias will generally increase and vice versa. How do we decrease bias with ensembling approach?
Boosting
One approach for reducing bias in our machine learning predictions is the boosting approach. Unlike bagging, where we can train our base classifiers in parallel on different samples data, the boosting approach requires sequential training of machine learning models.
These are the usual steps that we take when building a boosting machine learning model:
- we sample a set of instances from the data
- we build and train the base model on these instances
- trained base model is used to make predictions on the whole data set
- changes with respect to predictions are determined
- data instances with high deviations (predictions vs. labelled values) are given a larger weight in modified data set
- we build and train the next base model on these modified set of instances where some instances from 5. have larger weights
- we repeat steps 1 to 6. as long as some objective is not achieved
Historically boosting is related to the question posed by Kearns and Valiant: can we take a set of weak learners and build a strong learner from them. Subsequent work has proven them right and there have been many boosting algorithms developed since then.
Some of the well known boosting algorithms include:
- AdaBoost
- Gradient boosting
- XGBoost or Extreme Gradient Boosting
Stacking
Stacking approach uses two types of machine learning models. A collection of base models and a meta model which is trained on predictions of the base models.
An example of stacking base model and meta model:
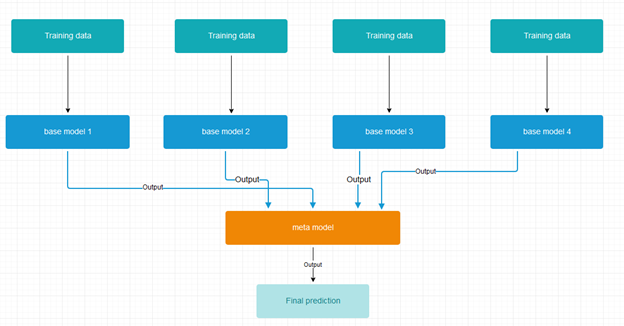
For meta model we can use simpler models like logistic regression, linear lasso regression or more complex models like XGBoost.
The training for the stacking model consists of two key steps:
- first, we train base models with k-fold validation and we set aside the out of fold predictions of the base models
- next, we train the meta model on these out of fold predictions of the base models
Blending
Blending is very similar to stacking, the difference is in how the train data set is used.
Stacking as we mentioned uses the out of fold predictions, blending on the other hand, uses the held out validation set for that, typically 10% of instances are used for this purpose.

Get in Touch
Do you need consultation or have a project in mind? We would love to hear from you!