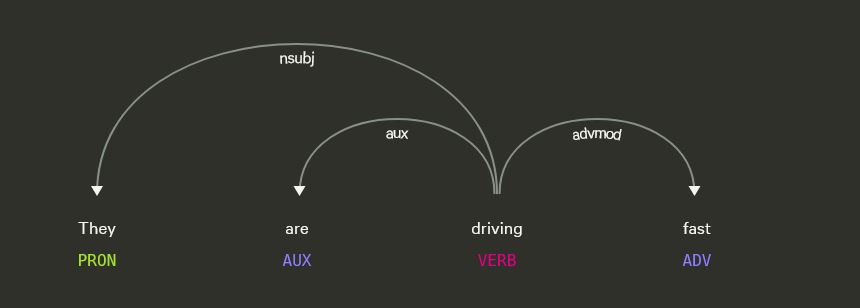
Sentiment analysis has emerged in recent years as an excellent way for organizations to learn more about the opinions of their clients on products and services.
A lot of both structured and unstructured data that companies gather during their operations contain subjective opinions or sentiments of their customers.
Such data can reside in emails, chat logs, social media posts, transcriptions of phone conversations with call centers. These vast troves of data are excellent sources for various data mining algorithms to produce valuable feedback and insights for the companies.
Early solutions in sentiment analysis field focused on determining the overall sentiment or sentiment polarity of text units, like sentences, paragraphs or documents.
In recent years, machine learning methods were developed for sentiment classification that allow a more granular opinion mining. An important part of this was accomplished with SemEval – international workshops on semantic evaluation. A particular important was SemEval2014, which as part of Task 4, assigned the tasks for Aspect Based Sentiment Analysis (ABSA).
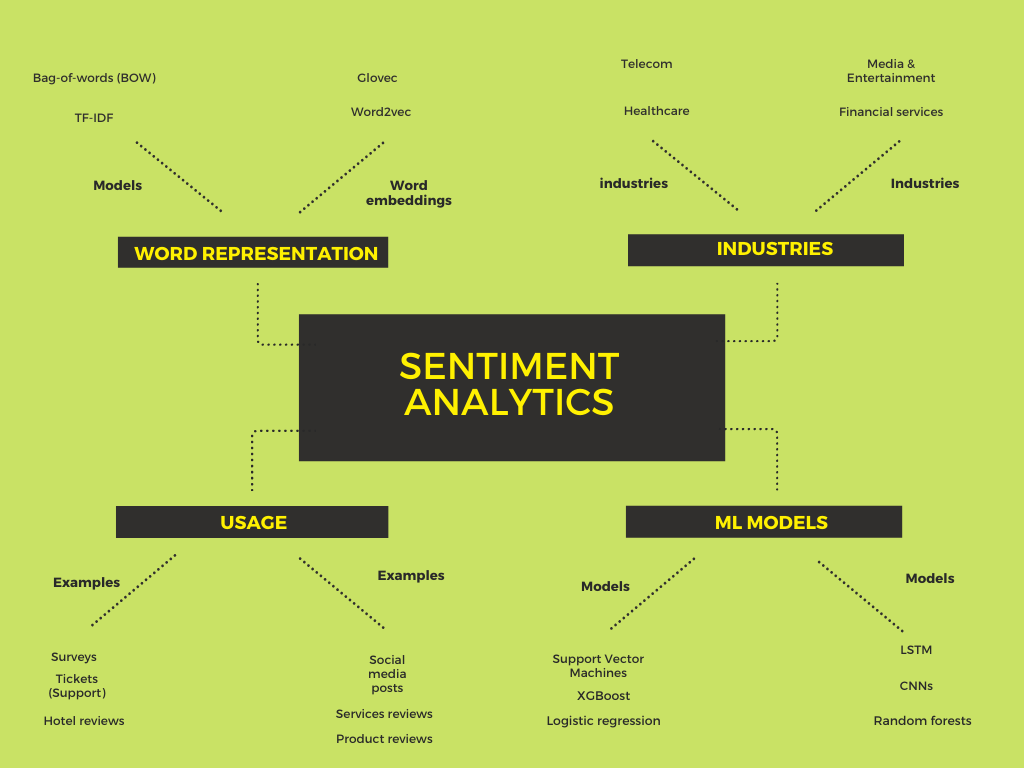
Aspect Based Sentiment Analysis allows the companies to obtain more information about the customer opinions, in particular, it allows us to extract:
- products mentioned in customer opinions
- specific aspects of products or services that are mentioned in opinions (e.g. for laptop, the features would be price, performance, screen quality)
- the sentiment on these specific aspects as determined from customer opinions
Detailed Opinion Mining using Aspect Based Sentiment Analysis
Technically, the ABSA approach accomplishes these tasks by using a combination of methods:
- extraction of relevant entities (e.g. hotels, restaurants, etc.)
- extraction of features and aspects of these entities (for hotels aspects could be location, price, service)
- use of aspect terms to determine the sentiment of a specific feature or aspect
Given a class of entities, e.g. hotels, how do we approach the problem of determining its aspects? Although one could use deterministic, domain-based rules, the vastly superior approach to this problem is to employ the natural language processing models.
One effective approach to aspect extraction is dependency parsing.
Using dependency parsing to extract aspects of entities
Dependency parsers are tools that allow us to analyze sentences, with particular focus on their grammatical structure. When analyzing and parsing the sentences, dependency parsers are looking for the so-called “head” words and show us how those head words depend on other words and in particular, how other words “change” or “modify” the head words.
There are excellent NLP libraries to perform dependency parsing of sentences, two excellent ones are:
- Spacy
- Stanford CoreNLP
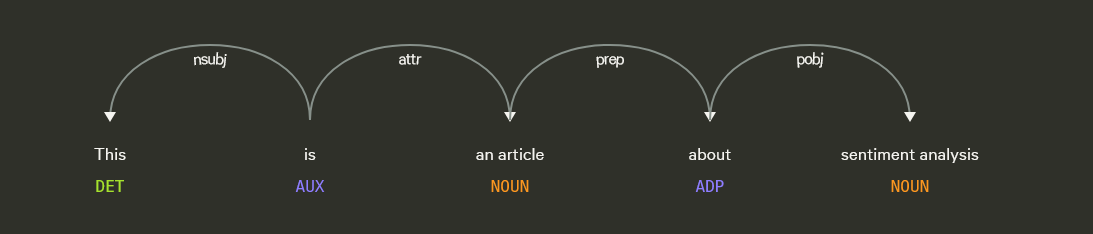
This is an example of dependency parsing the sentence of “This is an article about sentiment analysis”:
Opinion mining – where can we use it
Companies and organizations apply sentiment analysis on many different structured and unstructured data:
- social media posts, e.g. tweets, instagram posts
- reviews of products and services
- restaurant reviews
- surveys
- hotel reviews
- transcribed phone conversations (obtained by employing speech recognition models)
- emails
- tickets
Machine Learning model for sentiment analysis API
Sentiment analysis or determining sentiment polarities of aspects or whole sentences can be accomplished by training machine learning or deep learning models on appropriate data sets.
In the second part of the article, we will show you how train a sentiment classifier using Support Vector Machines (SVM) model.
To train sentiment classifier we will need the following steps:
- prepare a labelled dataset used for training
- select a machine learning model that is particularly suitable for text classification tasks
- train the specified ML model on the data set, split in train and test data
- evaluate results with confusion matrix (we are dealing with classification) and calculating precision, recall and f1-score
Sentiment classification model based on Support Vector Machines (SVM)
To build a sentiment classifier, we will use Support Vector Machines (Scikit-learn implementation).
To train the model, we will be using the Stanford 140, it is downloadable from:
http://help.sentiment140.com/for-students
Data is in a table with 6 fields:
0 – the polarity of the tweet (0 = negative, 2 = neutral, 4 = positive)
1 – the id of the tweet
2 – the date of the tweet
3 – the query. If there is no query, then this value is NO_QUERY.
4 – the user
5 – the text of the tweet
The required libraries are:
import pandas as pd from IPython.display import display from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import learning_curve from sklearn.externals import joblib
To use the Stanford 140 data set for training, we first need to remove some columns that we do not need and pre-process the texts of tweets:
def clean_tweets(df):
df['Text']=df['Text'].str.lower()
df['Text']=df['Text'].apply(lambda x: ' '.join(re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)"," ",x).split()))
return df
# preprocess data
df=pd.read_csv('training.csv',encoding='ISO-8859-1')
df.columns=['Sentiment','Id','Date','Query','User','Text']
del df['Id'], df['Date'], df['Query'], df['User']
df['Sentiment']=df['Sentiment'].map({0:'Negative',2:'Neutral',4:'Positive'})
df = df.sample(frac=0.1).reset_index(drop=True)
df=clean_tweets(df)
Machine learning models expect numerical or categorical representations for input features. Our main feature in this problem are texts of tweets.
Numerical representation of texts – Bag-of-Words (BOW)
We have several options for numerical representation of our tweets. One of the simplest is the so-called Bag-of-Words (BOW) representation. With BOW approach, we first extract the unique words in a given corpus of documents and then represent each document in corpus with a vector, where vector components correspond to words in corpus and are proportional to number of times the word appears in the document, BOW vectors are usually normalized to 1. BOW approach is one of the simplest approaches of text representation, it does not take into account the grammar of sentences and words order.
Term frequency inverse document frequency (TF-IDF)
A more complex approach, which often delivers excellent results is Term frequency inverse document frequency or TF-IDF. TF-IDF measures two aspects about a word in given document. Term frequency – how often a word appears in the document. And inverse document frequency, which diminishes importance of words that appear often in all documents of the corpus. The more a given word appears in other documents, the less relevant is the word for the particular document. TF-IDF is the product of both metrics and is normalized so that the values add up to 1 for given document.
Simpler models like BOW are essentially representing words with one hot encoding. There are several drawbacks to this. First is poor scalability – the size of vectors is equal to vocabulary, which may become very large with big corpus. As most of words will not be present in a document, the vectors will mostly contain zeros (sparse). Semantic meaning is disregarded – words that are similar in meaning will not have similar vectors.
Word embeddings – Word2vec
Word embedding is an approach that solves several of these drawbacks. It represents the words as vectors with manageable number of dimensions – for word2vec one can typically use 100 to 300. It also learns the representations of the words in a way that semantically similar words have similar, more closely aligned vectors. Word2vec is a two layer neural net which takes corpus of texts as input and produces a set of vectors, with one vector for each word in the corpus.
Word2vec can be trained by two approaches: skip-gram and continuous bag-of-words (CBOW). In skip-gram approach, context words are predicted using the input word. With CBOW, the target word is predicted using the context words.
Word2vec vectors have beneficial properties in terms of semantic meanings. In often cited example, king-man when computed in terms of vectors leads to similar vector as queen-woman.
TF-IDF representation of texts
In our case, we will skip the simpler BOW representation and use TF-IDF representation of tweets:
# preparing training, test data X=df['Text'].to_list() y=df['Sentiment'].to_list() X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.20, random_state=10) Vectorizer = TfidfVectorizer(max_df=0.9,ngram_range=(1, 2)) TfIdf=Vectorizer.fit(X_train) X_train=TfIdf.transform(X_train)
Training the SVM model
We next train the model using the linear SVM from scikit-learn:
# training the model model =sklearn.svm.LinearSVC(C=0.1) model.fit(X_train,y_train)
After converging, we can evaluate the accuracy of the model by calculating precision, recall and f1-score:
# evaluation X_test=TfIdf.transform(X_test) y_pred=model.predict(X_test) y_test=le.transform(y_test) print(classification_report(y_test, y_pred))
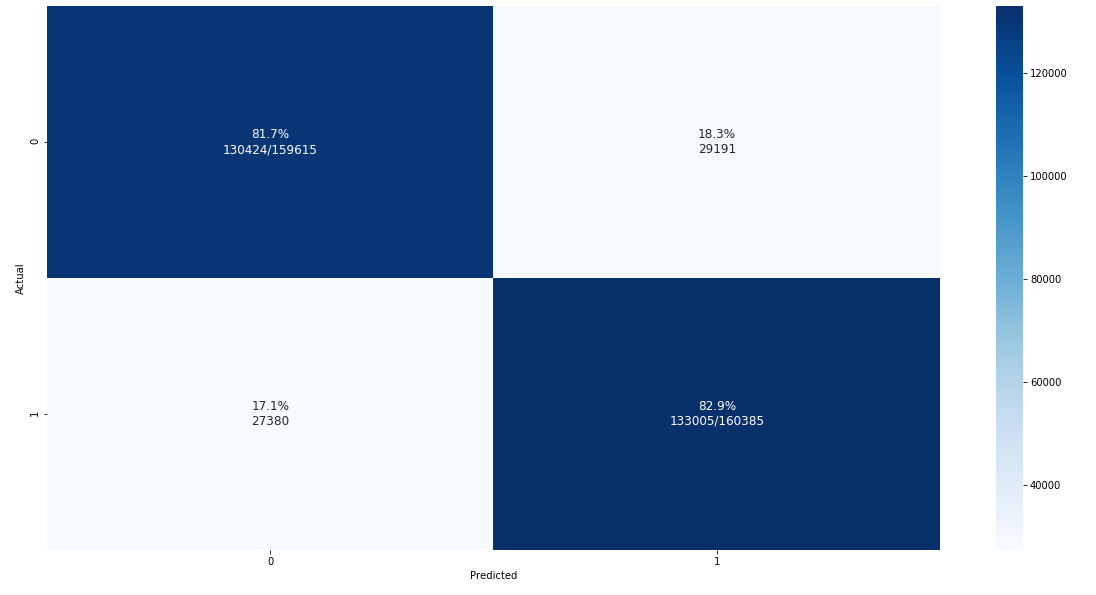
The sentiment classifier trained on Stanford 140 data set has a relatively good accuracy of 82%:
precision recall f1-score support
0 0.83 0.82 0.82 159615
1 0.82 0.83 0.82 160385
micro avg 0.82 0.82 0.82 320000
macro avg 0.82 0.82 0.82 320000
weighted avg 0.82 0.82 0.82 320000
Confusion matrix for the problem, determined on test set:

Get in Touch
Do you need consultation or have a project in mind? We would love to hear from you!