Natural language processing with python – POS tagging, dependency parsing, named entity recognition, topic modelling and text classification
This is the second part of our article series on the topic of Natural Language Processing (NLP).
In our first article, we introduced the natural language processing field, its main goals, as well as some of the NLP applications that we encounter in our everyday lives, such as machine translation, automated question answering or speech recognition.
We also provided an overview of several key methods used in NLP tasks: text pre-processing, feature extraction (bag of words, TF-IDF, hashing trick) and word embeddings.
In our second article on NLP, we will continue the discussion by focusing on several advanced methodologies that often form an important of NLP solutions – part-of-speech tagging, dependency parsing, named entity recognition, topic modelling and text classification. We will also discuss top python libraries for natural language processing – NLTK, spaCy, gensim and Stanford CoreNLP.
Part-of-Speech tagging
Part-of-speech tagging (POS tagging) is the process of classifying and labelling words into appropriate parts of speech, such as noun, verb, adjective, adverb, conjunction, pronoun and other categories.
POS Tagging techniques are generally classified into two groups: rule based and stochastic POS tagging methods with stochastic methods generally providing better results than rule-based ones.
Rule based approaches generally use the context of the word, e.g. surrounding words to determine the appropriate POS tag.
A common trait of the stochastic approach to POS tagging is use of probabilities. E.g. one can label the word with a tag that occurs most frequently in the training data set. Another example is the so-called n-gram approach or contextual approach, where the best tag for a word is selected based on the probability of this tag occurring with the n preceding tags.
Part-of-speech tagging for texts can be generated by python libraries, such as NLTK and spacy. An implementation using NLTK:
import nltk
tokens = nltk.word_tokenize('We are eating at a restaurant with our friends.')
print("POS tagging of sentence: ", nltk.pos_tag(tokens))

Figure 1: Part-of-speech tagging for a sentence (using NLTK library)
with NLTK notations:
- PRP – pronoun, personal,
- VBP – verb, present tense, not 3rd person singular,
- VBG – verb, present participle or gerund,
- IN – preposition or conjunction, subordinating,
- DT – determiner,
- NN – noun, common, singular or mass,
- NNS – noun, common, plural.
Part-of-speech tagging is an important method that helps us in many different natural language processing tasks.
It is e.g. used in the text to speech conversion. If a sentence includes a word which can have different meanings, with different pronunciations, then POS tagging can help in generating correct sounds in the word.
Another reason for using part-of-speech tagging is word sense disambiguation. Consider the following two sentences:
- A bear was charging towards the car.
- Your plans may be about to bear
The word bear has different meanings in both sentences. In one case it is a noun and in the other it is a verb. Using POS tagging can help with word sense disambiguation in this and other similar cases.
Dependency Parsing
Part-of-speech tagging labels words in a text with their correct grammatical tags. We are however often interested not only in part-of-speech tags of words, but also in relations between words.
Dependency parsing is an approach that helps us identify the relations in sentences, between so-called “head” words and words, which modify those head words.
An example of dependency parsing, using spacy library:
from spacy import displacy
sp = spacy.load('en_core_web_sm')
sentence = sp(u"We are eating at a restaurant with our friends.")
displacy.render(sentence, style='dep', jupyter=True, options={'distance': 75})
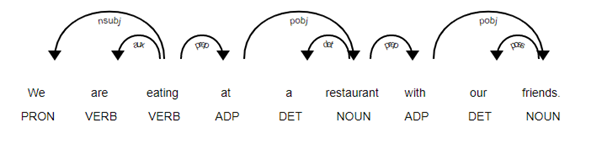
Figure 2: Dependency parsing of a sentence (using spacy library)
Named Entity Recognition
Named entity recognition (NER) is another important task in the field of natural language processing. It concerns itself with classifying parts of texts into categories, including persons, categories, places, quantities and other entities.
The main approaches to named entity recognition include the lexicon, rules-based and machine learning. Lexicon-based techniques can use gazetteers, which are advantageous when e.g. dealing with group of unique entities. Most modern NER systems are however based on machine learning models.
NER can be implemented with several NLP libraries, an example using spacy:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = str(‘Washington, D.C. is the capital of the United States. Apple is looking at buying startup for 2 billion. Angela Merkel is chancellor of Germany. ‘)
sentence = nlp(doc) print([(word, word.ent_type_) for word in sentence if word.ent_type_]) displacy.render(sentence, style='ent', jupyter=True)

Figure 4: Named entity recognition using spacy
Spacy library supports identification of many different types of entities:
| Type | Description |
| PERSON | People, including fictional. |
| NORP | Nationalities or religious or political groups. |
| FAC | Buildings, airports, highways, bridges, etc. |
| ORG | Companies, agencies, institutions, etc. |
| GPE | Countries, cities, states. |
| LOC | Non-GPE locations, mountain ranges, bodies of water. |
| PRODUCT | Objects, vehicles, foods, etc. (Not services.) |
| EVENT | Named hurricanes, battles, wars, sports events, etc. |
| WORK_OF_ART | Titles of books, songs, etc. |
| LAW | Named documents made into laws. |
| LANGUAGE | Any named language. |
| DATE | Absolute or relative dates or periods. |
| TIME | Times smaller than a day. |
| PERCENT | Percentage, including ”%“. |
| MONEY | Monetary values, including unit. |
| QUANTITY | Measurements, as of weight or distance. |
| ORDINAL | “first”, “second”, etc. |
| CARDINAL | Numerals that do not fall under another type. |
Topic Modelling
Topic modelling is an unsupervised approach to discovering a group of words or topics in large collections of documents.
One of the underlying assumptions of topic modelling techniques is that a document can be modelled as a mixture of topics, and each topic consists of a group of words. The texts are thus assumed to consist of some “latent” or “hidden” topics and the goal of topic modelling is to identify them.
Among the most popular topic modelling techniques are Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA).
Latent Semantic Analysis
LSA assumes that two words which have a similar meaning will occur in similar contexts, also known as the distributional hypothesis. LSA uses a bag of words approach and calculates the frequency of words in documents and the whole corpus. Based on assumption above, we can expect that similar documents will have similar frequency distribution for specific words.
On a technical level, LSA computes a document-term matrix with rows corresponding to document in the collection and columns corresponding to terms. This document-term matrix is then decomposed, using singular value decomposition, into the product of U*S*V.
Matrix V consists of vectors which capture the relations between terms with similar semantic meaning. Let us say that we have 4 terms that frequently occur together in the documents of the corpus, then it is highly likely that LSA will lead to a vector in matrix V with large weights for those four words.
Latent Dirichlet Allocation
As already noted above, Latent Dirichlet Allocation (LDA) is based on two guiding principles:
- document is a statistical mixture of topics,
- topic is a statistical mixture of words.
LDA assumes that the documents are produced as follows:
- choose number of words in the document,
- choose a mixture of topics for the document,
- generate words in a document by repeating the following steps as many times as target number of words:
-
- select a topic
- generate a word for given topic using the probabilities of words for this topic
The key difference between LSA and LDA is that the latter assumes that both topics distribution and word distributions for topics are Dirichlet distributions, whereas LSA does not make any assumptions on distributions.
Text classification
Another approach to determining topics in a text is using a supervised approach of text classification with pre-selected topics. Text classification can be more general, however and encompasses all methods that assign tags or labels to texts.
Assigning categories of texts allows us to filter text from emails, web pages, news, social media, chats, surveys and others. In one of our previous articles on our blog, we have already discussed and implemented an important text classification task – sentiment analysis, applied to a Twitter sentiment corpus. Other important applications of text classification include language detection, spam detection, user intent detection, website categorization and product categorization.
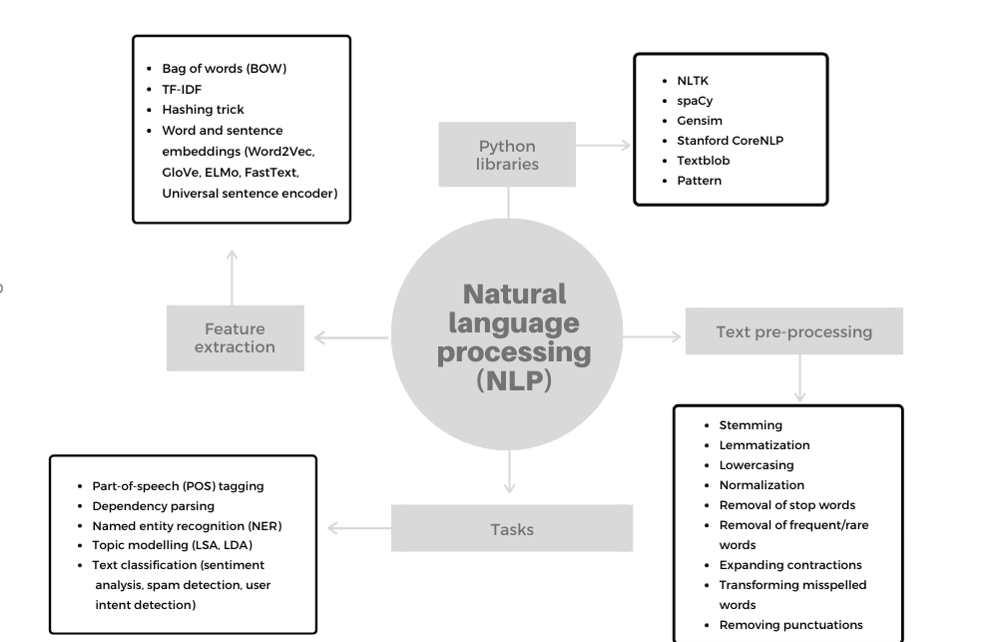
Figure 3: Natural language processing
NLP libraries
With the high complexity of natural language processing tasks, the natural language processing libraries play an even more important role when compared to some other fields where one can often resort to “coding from scratch” when confronted with the absence of an appropriate library.
Although there are many python libraries for NLP related tasks, there are 4 that stand out in terms of quality and breadth of features offered:
- Natural Language Tookit or NLTK
- Gensim
- spaCy
- Stanford CoreNLP
NLTK
NLTK (Natural Language Toolkit) is one of the leading platforms for natural language processing (NLP) with Python. It provides a wide range of methods for tokenization, tagging, parsing, stemming, classification and semantic understanding. One of its strengths is over 50 corpora and resources, including WordNet. NLTK also provides interfaces to other frameworks such as StanfordPOSTagger.
Gensim
Gensim is one of the most popular libraries for natural language processing. Its name “Topic Modelling in Python” shows strong support for topic modelling with integrated methods such as Latent Semantic Analysis and Latent Dirichlet Allocation. Since its beginning it has evolved in a versatile toolbox offering many other advanced NLP methods, including document index, similarity retrieval and support for many word embeddings, such as Word2Vec and GloVe.
spaCy
spaCy is a relative newcomer to the natural language processing space, when compared to older packages such as NLTK. Its developers have however included an impressive range of advanced NLP methods with fast implementation in Cython. spaCy comes with a large selection of pretrained statistical models and word vectors. It supports part-of-speech tagging, labelled dependency parsing, syntax-driven sentence segmentation, string-to-hash mappings, with visualizers for syntax and NER.
Stanford CoreNLP
Stanford CoreNLP is a widely used natural language analysis library. Although written in Java, there are several wrappers available for Python. It includes many advanced NLP tools, including part-of-speech tagger, the named entity recognizer (NER), parser, coreference resolution methods, sentiment analysis and open information extraction tools. It supports many major human languages and has APIs available for most major programming languages.
Conclusion
In our second article on natural language processing, we presented several important methodologies, often encountered in NLP tasks and introduced four popular python libraries for NLP.
NLP has achieved several remarkable successes in recent years, with some of them, like neural machine translation and speech recognition used by billions of people every day in digital assistants on mobile phones and other devices. Natural language processing will continue to be a very active field with a subfield of NLP, called natural language understanding (NLU) playing an especially important part in our aspirations to achieve artificial general intelligence (AGI).