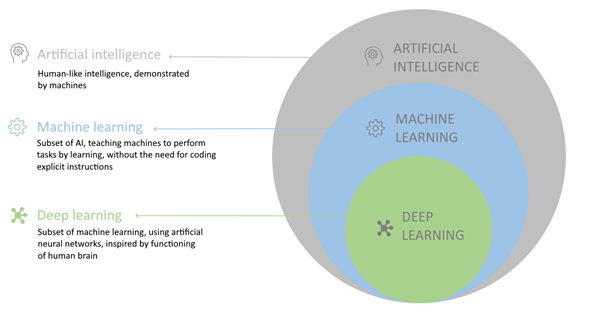
Introduction
Natural language processing is the field of using computers to understand, generate and analyze human natural language. On the most basic level, machines operate with 0s and 1s, so we in order for machines to understand and process human language, the first step is to map our speech and texts to numerical form.
In order to do that, however, we want to select a method where the semantic relationships between words are best preserved and for numerical representations to best express not only the semantic but also the context in which words are found in documents.
Word embeddings is a special field of natural language processing that concerns itself with mapping of words to numerical representation vectors following the key idea – “a word is characterized by the company it keeps”.
To generate word representations, one can use methods like bag of words or term frequency-inverse document frequency (TF-IDF). In this article, we will however focus on word embedding methods which are more advanced in nature.
Word embeddings
One of the most popular word embedding techniques, which was responsible for the rise in popularity of word embeddings is Word2vec, introduced by Tomas Mikolov et al. at Google.
Word2vec
Word2vec is based on a shallow, two-layer neural network, which takes as input a corpus of texts and produces as the result a vector for each word that is represented in the corpus.
The key feature of the shallow neural network that is learned is – words that often occur in similar contextual locations in the corpus also have a similar location in the word2vec space. As words that have similar neighbour words are likely semantically similar, this means that the word2vec approach is very good at retaining semantic relationships.
A famous illustrative example is that of the relation »Brother«-»Man«+«Woman« – using Word2Vec vectors of these words, the result of the vector mathematical operation is closest to the vector of word »Sister«.
There are two major Word2vec embeddings methods. While typical machine translation models predict the next word based on prior words, word embeddings are not limited in a similar way. Word2vec authors thus used both n words preceding the target word as well as m words after the target word (see Fig. 1) in an approach known as continuous bag of words or CBOW approach.
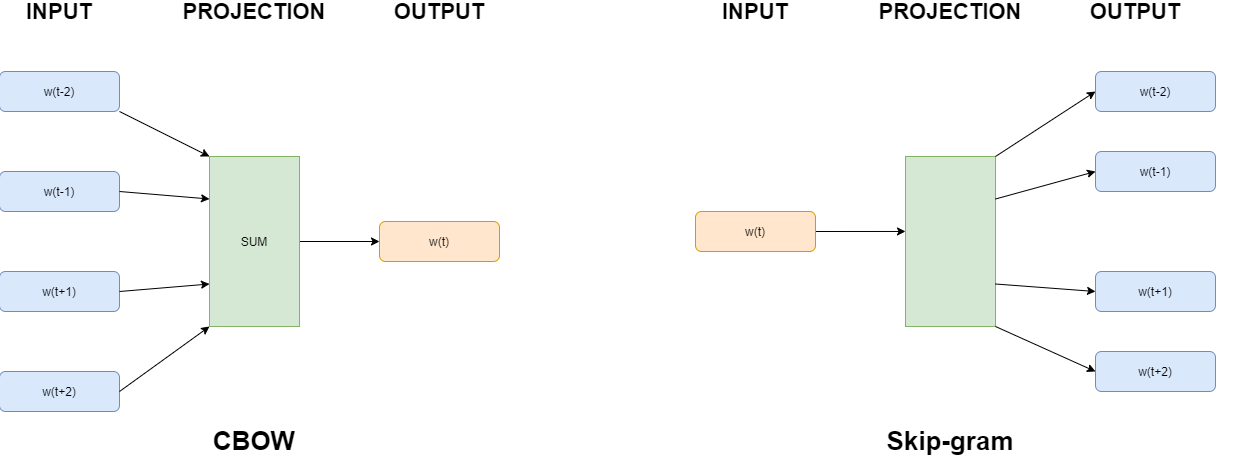
Figure 1: Word2Vec – continuous bag of words (CBOW) and Skip-gram
A second approach to Word2Vec is called Skip-Gram model and is based on predicting the surrounding words from the current word.
There are several excellent libraries available that implement Word2Vec approach, one of the most popular is gensim. Here is a condensed example of code for how to train your own custom Word2Vec model as part of your machine learning project:
word2vec_size = 300 word2vec_model = gensim.models.word2vec.Word2Vec(size=word2vec_size,window=5,min_count=5, workers=4) word2vec_model.build_vocab(X_texts) word2vec_model.train(X_texts, total_examples=len(X_texts), epochs=35)
One can also use a pre-trained Word2Vec models, with the most popular one is a word vector model with 300-dimensional vectors for 3 million words and phrases. The model was trained on part of the Google News dataset (about 100 billion words) and can be downloaded from:
https://code.google.com/archive/p/word2vec/
GloVe
GloVe is also a very popular unsupervised algorithm for word embeddings that is also based on distributional hypothesis – “words that occur in similar contexts likely have similar meanings”.
GloVe learns a bit differently than word2vec and learns vectors of words using their co-occurrence statistics.
One of the key differences between Word2Vec and GloVe is that Word2Vec has a predictive nature, in Skip-gram setting it e.g. tries to “predict” the correct target word from its context words based on word vector representations. GloVe on is however count-based.
It first constructs a matrix X where the rows are words and the columns are contexts with the element value X_ij equal to the number of times a word i appears in a context of word j. By minimizing reconstruction loss, this matrix is factorized to a lower-dimensional representation, where each row represents the vector of a given word.
Word2Vec thus relies on the local context of words, whereas GloVe utilizes global statistics on word co-occurrence to learn vector representations of words.
Fasttext
FastText was introduced by T. Mikolov et al. from Facebook with the main goal to improve the Word2Vec model. The main idea of FastText framework is that in difference to the Word2Vec which tries to learn vectors for individual words, the FastText is trained to generate numerical representation of character n-grams. Words are thus a bag of character n-grams.
If we consider the word “what” and use n=3 or tri-grams, the word would be represented by the character n-grams: <”wh”,”wha”,”hat”,”at”>. < and > are special symbols that are added at the start and end of each word.
By being based on this concept, FastText can generate embedding vectors for words that are not even part of the training texts, using its character embeddings. As the name says, it is in many cases extremely fast. FastText is not without its disadvantages – the key one is high memory requirement, which is the consequence of creating word embedding vectors from its characters.
FastText framework is open sourced, available at:
https://github.com/facebookresearch/fastText.
ELMo
ELMo is another popular word embedding framework. It was developed at Allen Institute for AI. It addresses the fact that the meanings of some words depend on the context. Consider the word “desert” in the following two sentences:
“Let us stick to this. “
“Fetch this stick.”
Both Word2Vec and GloVe would generate the same vector for word “stick”, although the meanings are different in both sentences. This is the shortcoming that is addressed by the ELMomethod.
ELMo does not produce a fixed vector representation for a word. Instead, ELMo considers the entire sentence before generating embedding for each word in a sentence. This contextualized embedding framework produces vector representations of a word that depends on the context in which the word is actually used.
ELMo uses a deep bi-directional LSTM language model giving the model a better understanding of not only the next words, but also the preceding ones. One distinction from traditional neural language models is that ELMo maps tokens to a representation by using character embedding, which are passed through the convolutional neural network and highway network with the result then passed to the LSTM layer.
Conclusion
Machine learning algorithms expect the input data to be in a numerical representation. Texts can be encoded with a wide range of methods, from simple ones like bag of words approach (BOW) and good results can often be achieved with the TF-IDF method.
Further improvement in recent years was development of Word2Vec and GloVe, both based on distributional hypothesis or observation that words that occur in the same contexts often have similar meanings. FastText framework soon followed which allowed generating good vector representations for words that were either rare or did not appear in the training corpus.
ELMo successfully addressed the shortcoming of the earlier models that could not appropriately consider that the meaning of some words depends on the context.
Development of word embeddings as well sentence embeddings is an important subfield in the natural language processing, and we expect further important breakthroughs in this field in the near future as well as for it to play an important role in various NLP applications.