Recommender systems are methods that predict users’ interests and make meaningful recommendations to them for different items, such as songs to play on Spotify, movies to watch on Netflix, news to read about your favourite newspaper website or products to purchase on Amazon.
Recommender systems provide valuable help to users and platforms, especially in settings where there is a very large number of users that can buy or interact with a very large number of items. Typical example of a such an online platform is Amazon, which as of April 2019 stored 119 million different products and had over 150 million users of just their mobile app in 2019, according to Statista. Amazon was also one of the earliest e-stores which implemented large-scale and advanced recommender systems, with great success.
An early indication of the important role of recommender systems for online platforms was also the open competition that Netflix started in 2006, the “Netflix prize”. The goal was a to develop a recommender system that could outperform its own, Nextflix algorithm and awarded with the grand prize of 1 million dollars. The competition was won by a BellKor’s Pragmatic Chaos team, which was better than Netflix’s own algorithm by around 10.1%.
Recommender systems generate recommendations based on information gathered on various interactions that users have with items, these can include, among others:
- ratings that users give to restaurants, movies, products or services,
- what content user viewed on a website, e.g. a news article,
- how much time user spent viewing a product,
- which event was attended by a user,
- which songs were played by the user,
- history of products or services purchased by the user.
A second group of information that recommender systems may use to inform their recommendations are user-specific information, such as age, sex or item-specific descriptions, in case of movies these can include movie’s title, director, movie plot, cast, related genres and others.
Recommender systems generally work by calculating relevancy of items for a user, ranking them and showing the most relevant to the user. If you have watched a lot of science fiction movies on Netflix lately, you will probably see more new movie suggestions from this genre. Or if you played a lot of songs on Spotify from a song genre, this may influence your next daily mixes.
Recommender systems can be distinguished primarily by the type of information that they use. Content-based recommenders rely on attributes of users and/or items, whereas collaborative filtering uses information on the interaction between users and items, expressed in the so-called user-item interaction matrix (see Figure 1).
Recommender systems are widely used in the most popular applications that we use every day, such as Netflix, Amazon, Facebook, YouTube and Spotify. In terms of sectors, they are especially often used in e-commerce, social media, content and media services.
Recommender systems are generally divided into 3 main approaches: content-based, collaborative filtering, and hybrid recommendation systems.
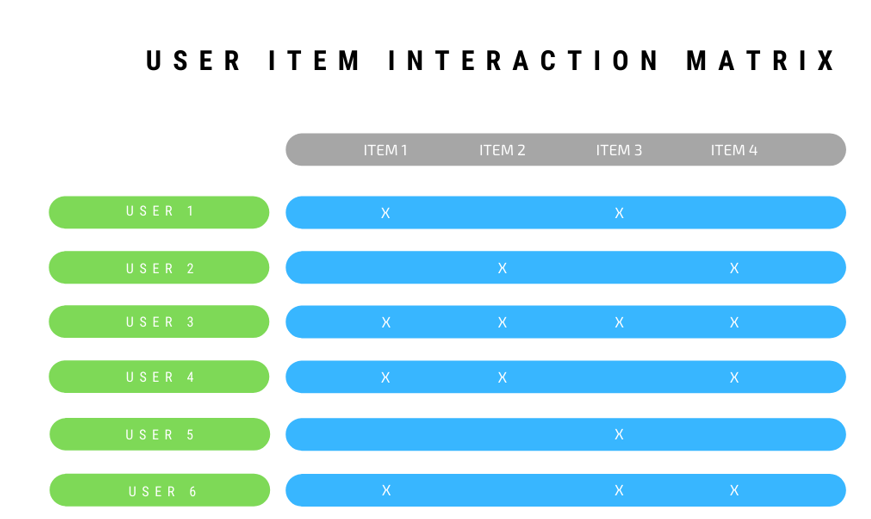
Figure 1: User-item interaction matrix
Content-based recommender systems
Content-based recommender systems generate recommendation by relying on attributes of items and/or users. User attributes can include age, sex, job type and other personal information. Item attributes on the other hand, are descriptive information that distinguishes individual items from each other. In case of movies, this could include title, cast, description, genre and others.
By relying on features, those of users and items, content-based recommender systems are more like a traditional machine learning problem than is the case for collaborative filtering. Content-based method uses item-based or user-based features to predict an action of the user for a given item. User’s action can be a specific rating, a buy decision, like or dislike, a decision to view a movie and similar.
One of the advantages of content-based recommendation is user independence – to make recommendations to a user, it does not require information about other users, unlike collaborative filtering. This makes content-based approach easier to scale. Another benefit is that the recommendations are more transparent, as the recommender can more clearly explain recommendation in terms of the features used.
Content-based approach also has its drawbacks, one is over-specialization – if the user is only interested in specific categories, recommender will have difficulty recommending items outside of this scope, leading to user remaining in its current circle of items/interests. Content-based approaches also often require domain knowledge to produce relevant item and user features.
How does one implement a content-based approach in practice?
Let us say we are interested in movies and have access to a large database with all the relevant attributes of movies: titles, descriptions, casts, genres and others. We want to build a content-based recommender system which will be able to produce recommendations for a given user.
One approach to building this system would be to first create an item feature which consists of all the relevant metadata for a movie. We could e.g. form a feature which incorporates movie’s title, genres, top 5 actors, director, movie description. After appropriate text pre-processing of individual attributes, we design the main item feature by concatenating the strings from all the considered attributes.
Our recommender system will be based on the concept of similarity, we therefore need a numerical representation of our resulting item feature. We can calculate numerical representation of our text by using a bag of words approach, TF-IDF, word embeddings, sentence embeddings or some other method. The choice should also depend on the features used. If we e.g. use actors, we may rather use count-based approach instead of TF-IDF as with the latter, the actors who acted in many films may get a reduced weight.
To create a personal profile that reflects user movie preferences, we can utilize the vector representation of movies that the user liked or highly rated, with personal profile vector being equal to average vectors of such movies, with vectors determined with TF-IDF or some other method, mentioned above.
Next, we compute cosine similarity between this personal profile vector and vector representation of each movie, followed by ranking them by similarity. The result is a personalized recommendation list of top-rated movies for our user, based on his/her past ratings.
In one of our next articles on the blog, we will present concrete implementation of this content-based recommender, using the MovieLens dataset.
Collaborative filtering recommender systems
Collaborative filtering methods focus solely on the past interactions of users with the items to generate recommendations. Past interactions of users with items can be purchase of a product, listening to a song, rating a product, watching a movie, clicking on a news article and similar.
These historical interactions are recorded in a user-item interaction matrix. Figure 1 shows an example of such a matrix, where elements in the matrix can either be numeric, e.g. movie ratings, or binary, e.g. denoting whether a user purchased the movie or not.
In many practical applications, item-user matrices are enormous, with hundreds of millions of rows and columns. They are very often sparse with most of the ratings in the user-item matrix missing and left to be predicted by the appropriate recommender system.
Collaborative filtering is based on the assumption that if a user X likes items A, B and another user Y likes the item A, B and C then the user X may also like the item C. This collaborative aspect of the method means that the accuracy of the collaborative filtering increases with the number of interactions of users with items.
There are two main types of collaborative filtering methods: memory-based and model-based (see Figure 2).
Memory-based collaborative filtering
Memory-based method does not build a model for interactions but rather directly uses the data on users’ past interactions to generate recommendations. Memory-based method can be further subdivided into user-based and item-based methods.
User-based
The user-based approach assumes that similar people have similar preferences. If a friend has seen very similar movies as myself and rated them similarly and I have seen and highly rated movie A, that she has not seen, then it is highly likely it might be interesting to her as well.
User-based approach thus first determines users that are most similar to “active” user. It then recommends to the active user the items that are the most popular among these “nearest neighbours”. The similarity measure between users is computed by approximating personal profiles of users as vectors of interactions of users with items. These vectors are represented by rows in the user-interaction matrix.
These personal profile vectors enable us to determine similarities of users by calculating e.g. cosine similarity between respective vectors.
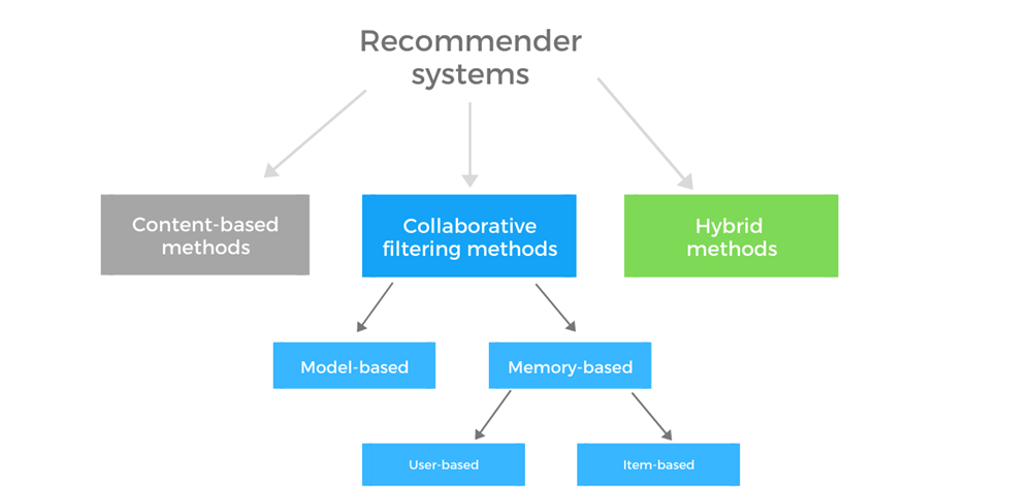
Figure 2: Types of recommender systems
Item-based
Item-based approach works in a similar way, except that it focuses on items instead of users. In this case, we want to recommend to an active user those items that are very similar to the ones that the user has already interacted with.
If the user has given the highest rating to the item X, we can numerically represent this item with the vector of interactions of all users with this item, represented by the column in the user-item matrix. We thus assume that two items are similar, if users interacted with them in a similar way, as represented by the respective columns. By computing similarities between the most liked item X of user and all “nearest neighbour” items, except those he/she already interacted with, ranking them by similarity, we obtain the recommendations for the user.
Although relatively easy to implement, a significant drawback of memory-based model is difficulties in scaling it, as the complexity of the problem is linear both in number of users as well as in a number of items, which both can be millions or more in typical systems.
Model-based collaborative filtering
Model-based method assumes a latent, lower dimensional model that can explain the user-item interactions and it uses this model to generate new recommendations.
One of the most popular model-based collaborative filtering methods is based on matrix factorization. The main idea behind matrix factorization approach is to reduce the usually large and sparse user-item interaction matrix A into a product of two smaller matrices which represent latent user representations and item representations:
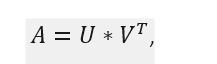
where U represents users and V the items. Once we compute the matrix factorization, information about how the user interacts with a given item can be computed by calculating product of respective vectors. U and V can be determined by several methods, most often used are a stochastic gradient descent and alternating least squares (ALS) method.
Collaborative filtering is more frequently used than content-based method and generally provides more accurate and better results than the latter.
An important advantage of collaborative filtering is that it does not need any attribute information about users and items. Disadvantage of the method is the inability of collaborative filtering to provide accurate recommendations when dealing with new users and/or new items. As collaborative filtering relies on past interactions for recommendations, it has a so-called “cold-start” problem – it cannot reliably recommend items to new users or new items to existing users.
There are several strategies available to lessen the cold-start problem:
- suggest most popular items to new users,
- suggest new items to random users,
- suggest random items to new users.
Another challenge for collaborative filtering is the “sparsity” of user-interaction matrix or the fact that many items have not been rated or interacted with by enough people to make reliable recommendations on them.
Hybrid recommender systems
We have seen that both content-based and collaborative filtering has several drawbacks which is one of the main motivations for the development of hybrid recommender systems, which are used by most of the large platforms, including Netflix. The main motivation behind combining approaches is to obtain a recommender which has fewer disadvantages than any of them.
There are several options for combining both approaches. One is a weighted recommender which produces the predictions of both methods separately and combines their results, using weights that can be modified using insights on the accuracy of predictions from repeated usage.
The next design of hybrid recommender is feature combination, which involves treating the collaborative filtering data as just another feature for the content-based recommender. In this way, the recommender does consider the collaborative aspect, but does not rely solely on it, so it does not suffer from the cold-start problem that is typical for “pure” collaborative filtering recommenders.
The cascade recommender approach is based on a pipeline of recommenders where the lower recommenders break ties that result from higher placed recommenders. By using prioritization, the lower recommenders do not influence or change well differentiated recommendations from upper recommenders and focus only on those recommendations which require further differentiation.
Meta level recommenders work by using the results of one recommender system as the input to another recommender system.
Switching recommenders use a rule to switch between different recommenders. Typically, switching recommenders switch between content-based and collaborative filtering with the goal of decreasing drawbacks of both approaches. They, however, introduce additional complexity to the problem – the rule and its parameters which govern the working of the recommender.
Benefits of recommender systems
Recommender systems bring considerable benefits both to platforms that operate them as well as users that use them.
One of the most important benefits is a personalized experience. When purchasing products, we very often rely opinions of others. 50 years ago, this may have been a shop employee, friends or family. Today, when confronted with literally millions of potential products to choose from, this role has in many cases been taken over by the recommender system.
By basing their recommendations on interactions of millions of users with often millions of items, recommenders can find patterns in big data and make recommendations that are highly meaningful to us and our personal preferences. The result is higher customer satisfaction, higher user engagement and customer loyalty on the side of users and better conversion rates, increased revenues for the platforms.
Conclusion
In this article, we have introduced recommender systems which help numerous online platforms deliver meaningful recommendations to its users, a song to listen, movie to watch, news to read or a product to buy.
Recommender systems utilize big data about our interactions with items and try to find patterns which show what items are most popular with users that are similar to us or find items that are most similar to items that we have purchased in the past.
Recommender approaches can be broadly divided into three groups. Content-based methods use attributes of users and/or items to make recommendations. Collaborative filtering relies on the interaction of users with items, encoded in the so-called user-interaction matrix and uses this collaborative aspect to make recommendations.
Hybrid approaches try to combine both main approaches in a way which minimizes the drawbacks of any of the individual methods. Hybrid recommenders are the most common type of recommenders, found in online platforms today.
The popularity of the recommender systems mainly derives from the considerable benefits that they bring to both users of platform as well as platform themselves. Users can enjoy personalized experience, tailored to their personal preferences. If using a high-quality recommender, users can often be positively surprised by the discovery of new, previously unseen items, that seem especially interesting to them, such as an exciting movie to watch or interesting song to listen to. Increased customer satisfaction, loyalty and retention bring considerable benefits to platforms as well, in the form of increased revenues and profits, resulting generally in a win-win situation for both users and operators of platforms.


