Artificial intelligence, machine learning and deep learning
The last decade has seen artificial intelligence deliver impressive results in areas ranging from image detection, automated driving to powering recommendations on e-commerce platforms as well as helping us in our everyday lives as part of personal digital assistants like Siri and Alexa.
When reading about artificial intelligence (AI) one quickly encounters two additional terms often used synonymously with AI – machine learning and deep learning. In this article, we will explain how three terms are related to each other, what is their significance and what type of applications are they powering that we use in our everyday lives.
Artificial intelligence is considered the broadest category, with machine learning a subset of artificial intelligence and deep learning in turn a subset of machine learning (see Fig. 1). All machine learning thus belongs to artificial intelligence, but not all machine learning is deep learning.
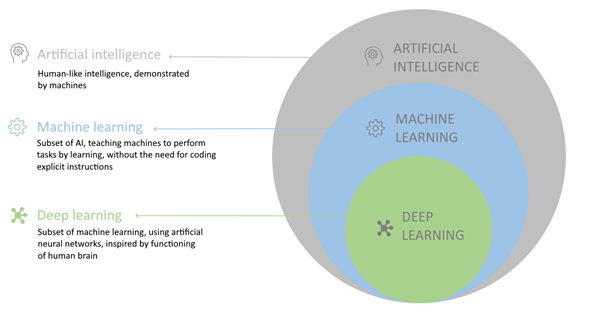
Figure 1: Artificial intelligence, machine learning and deep learning
Artificial Intelligence
Artificial intelligence was first introduced as a term in 1955 by John McCarthy as part of preparations for the Dartmouth conference that was held in 1956 and is often seen as the start of the artificial intelligence era.
In its proposal for the Dartmouth conference, the participants described artificial intelligence as:
“The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.”
Proposal for Dartmouth conference, 1956
Although there are many other definitions of what artificial intelligence represents, we can view AI as a discipline of building machines that are able to perform tasks that would normally require human intelligence. In other words, human-like intelligence but demonstrated by machines.
Artificial intelligence is further subdivided into two areas: strong, general AI, artificial general intelligence (AGI) and weak, narrow AI.
Strong AI describes development of machines that can perform all tasks on a level comparable or better than humans. Strong AI or AGI currently does not exist and it may take considerable time to achieve it, despite numerous organizations currently working on it and significant funding available for it.
The AI that we use and interact with it in our everyday lives is thus of another kind – narrow or weak AI (narrow AI is often classified as a subfield of weak AI).
Narrow AI are algorithms that excel at doing one task particularly well, on the same level or better than humans. However, narrow AI is excellent only at one task and does not perform well on other unrelated tasks.
A deep neural net trained on database ImageNet may e.g. be excellent at recognizing animals from images but would be useless when used for a task in another domain, such as translation between languages. All major examples of AI in use today, e.g. facial recognition, recommender engines, spam filters, self-driving cars, digital assistants like Siri, are examples of narrow AI.
We live in a narrow AI world and we will for some time until we see larger advances in AGI.
Machine Learning
Machine learning is a subset of AI that teaches machines to perform tasks by learning from experience. Instead of coding specific instructions on how the machines should perform certain task, we let them “learn” their behaviour on examples. The learning process of machines is automated, with performance of machines generally improving with experience and the amount of data ingested.
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E. –Tom Mitchell
Machine learning algorithms are often divided in three groups:
- supervised machine learning
- unsupervised machine learning
- reinforcement learning
In supervised learning, the model is trained on labelled data with each data instance having a known outcome. Supervised learning algorithms are further divided in classification (prediction of classes, e.g. whether an email is spam or not) and regression models (prediction of continuous outputs, e.g. prediction of sales in the next quarter).
Unsupervised learning describes algorithms for finding patterns in data, without prior knowledge of outcomes for data instances. Unsupervised learning includes clustering or finding groups of data instances that are similar to each other but distinct from data instances in other groups.
Unsupervised learning includes dimensionality reduction methods which play an important role in feature selection and feature engineering.
Finally, reinforcement learning describes decision and reward systems, which learn in an environment where they are rewarded for “good” actions and penalized for “bad” actions they take. Like unsupervised learning, reinforcement learning does not require prior knowledge of outputs for given input data.
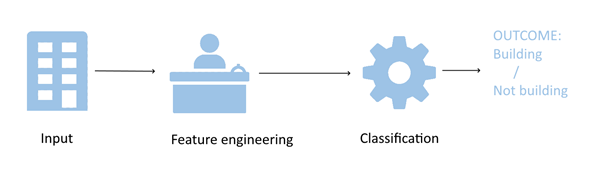
Figure 2: Classification with machine learning
Machine learning offers a wide range of both standard and advanced algorithms:
- Linear regression, standard statistical model, primarily used for regression problems,
- Logistic regression, used for classification tasks with strong performance even on complex problems and datasets,
- Decision trees, which are building blocks for many advanced algorithms such as Random Forests and Gradient Boosting Machines,
- K-means clustering algorithm – an example of unsupervised model and useful when trying to find patterns in large unlabelled data sets. Due to some drawbacks of K-means, several more advanced clustering models are available, such as Spectral Clustering or DBSCAN algorithm,
- Support Vector Machines (SVM) work by constructing a hyperplane or a set of hyperplanes and can be used both for classification and regression tasks,
- Random forests apply a bagging approach to decision trees to build ensemble learners that perform well on classification and regression tasks.
Deep Learning
Deep learning has become more widely known in general public through successes of AI in playing and beating humans in games, such as the 2016 win in game of Go by Google’s AlphaGo over South Korea’s Lee Seedol.
Although neural net models have been around for decades, many see year 2012 as the start of deep learning “revolution”, driven in important part by adoption of graphics processing units or GPUs for deep learning tasks.
Several significant improvements over prior best results were achieved in this period, including win by Krizhevsky et al. in large-scale ImageNet competition in October 2012.
Deep learning is based on neural network algorithms that were inspired by the functioning of neurons in human brains, although the latter are much more complex. Typical neural net consists of input, output layers and one or more hidden layers in between. Each layer consists of units, often called neurons, that transform input data to the layer to the output data that is used by the neurons in the next layer.
“Deep” in the term deep learning refers to the typically large number of hidden layers in deep neural nets. One of the benefits of multiple layers is that they can learn higher level abstractions or features from input data. When building a neural net for face detection, a group of neurons can e.g. learn to recognize eyes, another group a nose in the face, etc.
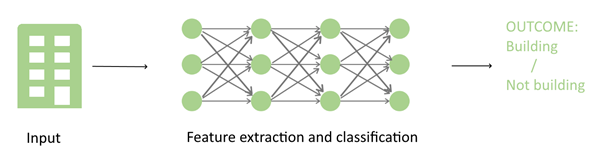
Figure 3: Classification with deep learning
Deep learning uses many types of neural networks, most common are convolutional neural networks (CNN) and recurrent neural networks (RNN). CNNs are usually used in computer vision tasks, such as image classification or object detection.
The main feature of recurrent neural networks is the feedback loop – the output from the previous step can be used as input in the current training step. RNNs are most often used in time series forecasting, natural language processing and speech recognition tasks.
Deep Learning vs. Machine Learning
Deep learning methods generally differ from machine learning methods in several areas. Whereas feature engineering and selection is an important and often time-consuming part of machine learning development, there is often no need for features engineering in deep neural nets.
With their complex architectures, neural nets are able not only to make predictions but also extract the relevant features from the input data. Feature extraction is thus part of the learning process (see Fig. 3). A typical example of feature extraction is edge detection performed by the first layers in the neural nets for computer vision tasks.
Other differences between typical machine learning (ML) and deep learning (DL) models:
- DL models generally require a lot more data than ML algorithms,
- unlike ML algorithms, training of DL models often requires use of GPUs to speed up training,
- DL models often require long training times,
- output of DL models is often complex – images, sound and, videos,
- DL models are typically much larger in size than ML models.
Conclusion
In the last decade, artificial intelligence has entered many parts of our lives, driven by successes in computer vision tasks, natural language processing and other areas. It can detect objects in autonomous driving systems, recommend products on e-commerce platforms, automatically translate texts between languages and many other tasks.
When describing artificial intelligence or AI, two other terms are often synonymously and interchangeably used for AI – machine learning and deep learning. In this article, we have more provided information on what each term describes, how they relate to each other and what are their most important differences.


